








Where can I find the latest cancer statistics?
29/05/14 15:14
We receive quite a few cancer research papers to edit, and it is not uncommon for authors to set the scene by presenting a few ‘critical’ cancer facts (such as incidence, prevalence, and mortality) in the opening lines of the introduction. There is nothing wrong with this (although we wouldn’t necessarily advise it if you are submitting to a highly specialised cancer journal), but it is important that the figures are correct. We often find that the ‘facts’ are, more often than not, wildly out of date, inaccurate, or incompletely referenced. Given the easy accessibility of online data, there really is no excuse for glaring inaccuracies and any sloppiness could irritate a reviewer.
That’s why we suggest that you visit GLOBOCAN, an online resource established and maintained by the International Agency for Research on Cancer (part of the WHO). The GLOBOCAN project provides current estimates of the incidence, mortality, and prevalence of major cancer types for 184 countries. The data can be separated by sex, and 1-, 3-, and 5-year prevalence data are available for the adult population.
The database is particularly useful since it can be queried using online analysis tools, which allow you to produce graphs, tables, and maps to illustrate data. These tools are likely to be particularly useful for theses and dissertations, where there is often a need to provide more comprehensive background to the subject and provide basic data.
For instance, let’s say that you need to prepare a graph that compares age-standardised incidence and mortality rates of female cancers in ‘developed’ and ‘developing’ regions. Easy!
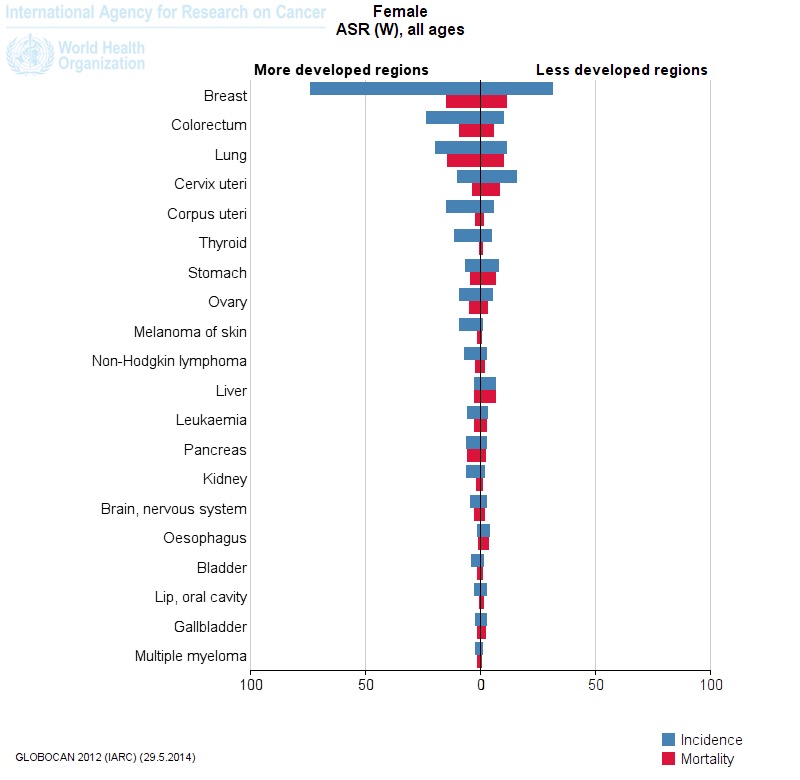
The graph clearly highlights those cancers that persist as first-world problems, such as breast cancer, and those cancers that more commonly affect women in the developing world (such as cervical cancer). This might provide an excellent starting point for a discussion about the epidemiology of these diseases.
GLOBOCAN can be referenced in your manuscript, and there is a useful glossary of terms, just in case you tend to get your ‘incidences’ and ‘prevalences’ mixed up. Of course, there are other excellent statistical resources available to cancer researchers, such as CRUK’s Cancer Stats resource in the UK or the NCI’s tools in the US. Please let us know if you know of any other resources that you find useful by commenting below!
comments powered by Disqus
That’s why we suggest that you visit GLOBOCAN, an online resource established and maintained by the International Agency for Research on Cancer (part of the WHO). The GLOBOCAN project provides current estimates of the incidence, mortality, and prevalence of major cancer types for 184 countries. The data can be separated by sex, and 1-, 3-, and 5-year prevalence data are available for the adult population.
The database is particularly useful since it can be queried using online analysis tools, which allow you to produce graphs, tables, and maps to illustrate data. These tools are likely to be particularly useful for theses and dissertations, where there is often a need to provide more comprehensive background to the subject and provide basic data.
For instance, let’s say that you need to prepare a graph that compares age-standardised incidence and mortality rates of female cancers in ‘developed’ and ‘developing’ regions. Easy!
The graph clearly highlights those cancers that persist as first-world problems, such as breast cancer, and those cancers that more commonly affect women in the developing world (such as cervical cancer). This might provide an excellent starting point for a discussion about the epidemiology of these diseases.
GLOBOCAN can be referenced in your manuscript, and there is a useful glossary of terms, just in case you tend to get your ‘incidences’ and ‘prevalences’ mixed up. Of course, there are other excellent statistical resources available to cancer researchers, such as CRUK’s Cancer Stats resource in the UK or the NCI’s tools in the US. Please let us know if you know of any other resources that you find useful by commenting below!
comments powered by Disqus
The World Databank - An Amazing Resource
20/02/13 13:01
Something we feel strongly about at Nextgenediting is the use of computational biology to support and contextualise the main experimental findings of a biological paper. There is a wealth of primary research that can be performed before you even get started doing your experiments in the lab, and the best papers know how to make the best use of it. These data can be particularly useful for grant applications, too. We sometimes send recommendations back to our biomedical authors saying ‘go to GEO and analyse this dataset - you have all the information available to you tell you exactly what the expression of your gene of interest is in thousands of breast cancers…or colon cancers…or cardiovascular patients….or whatever your disease of interest is’. When you take this approach you often find the experiment you were planning (in vitro or in vivo) has already been performed, or there is supporting mouse data, or often clinical data. They can be used to generate the first figure(s) of the paper, put the experimental data in clinical context, and save a huge amount of time and effort performing costly -omics experiments. If you don’t know how to use these resources or need more information, please contact us.
What we hadn’t realised until very recently was that the same can be done for epidemiological data. We are currently planning our Nextgenediting Global Initiative (for more information click here), and while researching health and income statistics of third-world countries we found the World Bank World Databank. This is a free, online database of Development Indicators, Gender Statistics, and other useful data, which you can mine and interrogate at will for hundreds of different countries - both developed and otherwise. Most exciting for us however, is the Health, Nutrition, and Population Statistics Database which allows you to mine health and disease-related data. You just choose your country or countries of interest, the data series you want, and the range of years you are comparing (from 1961 to present) and the results are presented as tables, graphs, or on a map. You can even download the raw data and work with it yourself to present your own graphs or figures. Truly amazing.
We remember feeling like this when we first realised we could get our hands on raw gene expression data. What a powerful tool to contextualise your own work.
So if, for instance, if you are doing a study on HIV, and you need to know what the AIDS death rates are in various African countries, it would take two minutes to get this chart:
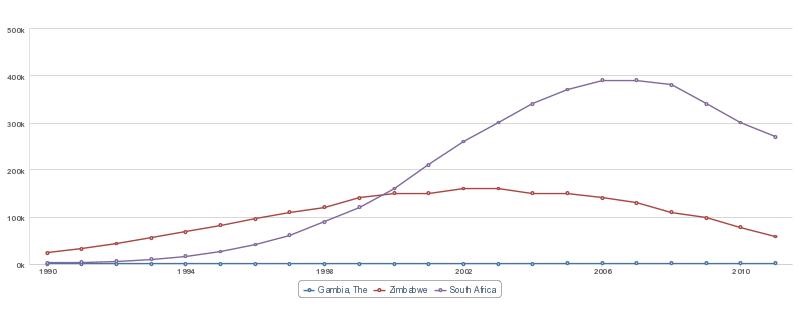
which you can then fully customise. So much better than some outdated and over-cited WHO data, don’t you think? You can then get a first-hand grip on the numbers, trends, and associations relevant to your own research.
The World Databank provide the following video tutorial, so please check it out:
We strongly recommend you go and have a play with this fabulous resource and see if it is useful for you. It’ll be particularly useful for students looking for thesis data. And please let us know what you think by commenting below.
comments powered by Disqus
What we hadn’t realised until very recently was that the same can be done for epidemiological data. We are currently planning our Nextgenediting Global Initiative (for more information click here), and while researching health and income statistics of third-world countries we found the World Bank World Databank. This is a free, online database of Development Indicators, Gender Statistics, and other useful data, which you can mine and interrogate at will for hundreds of different countries - both developed and otherwise. Most exciting for us however, is the Health, Nutrition, and Population Statistics Database which allows you to mine health and disease-related data. You just choose your country or countries of interest, the data series you want, and the range of years you are comparing (from 1961 to present) and the results are presented as tables, graphs, or on a map. You can even download the raw data and work with it yourself to present your own graphs or figures. Truly amazing.
We remember feeling like this when we first realised we could get our hands on raw gene expression data. What a powerful tool to contextualise your own work.
So if, for instance, if you are doing a study on HIV, and you need to know what the AIDS death rates are in various African countries, it would take two minutes to get this chart:
which you can then fully customise. So much better than some outdated and over-cited WHO data, don’t you think? You can then get a first-hand grip on the numbers, trends, and associations relevant to your own research.
The World Databank provide the following video tutorial, so please check it out:
We strongly recommend you go and have a play with this fabulous resource and see if it is useful for you. It’ll be particularly useful for students looking for thesis data. And please let us know what you think by commenting below.
comments powered by Disqus